Data Landscape Canvas
By using the Data Landscape Canvas you explore new data sources and discover new data suppliers. It helps you to assess your company data and to identify the proper data sources for your utilization scenarios.
We drive your business forward.
What Is the Data Landscape Canvas?
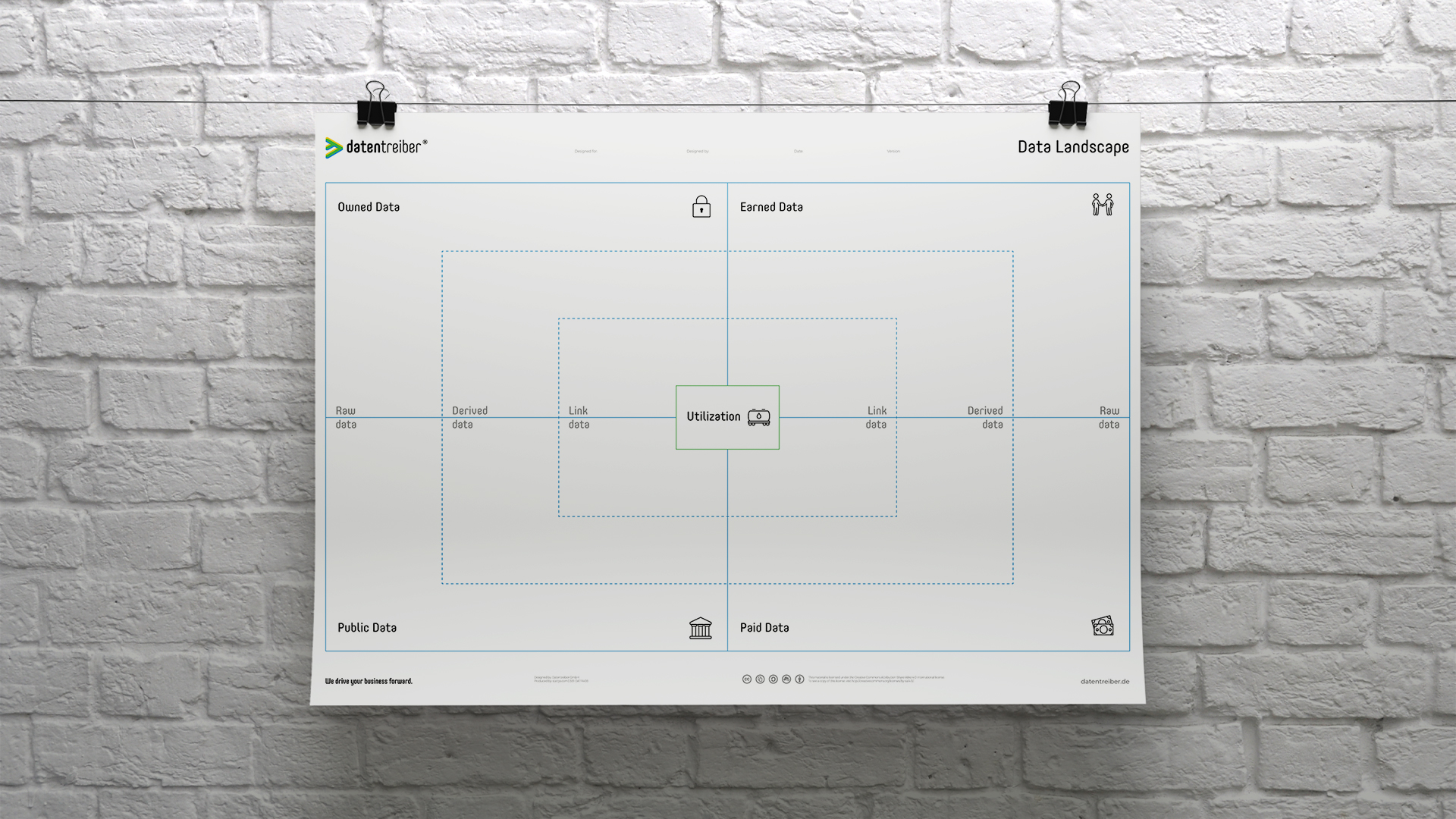
The Data Landscape Canvas complements the Data Strategy Canvas and delves into the question of data supply by classifying data sources according to their origin:
- Owned Data: which data is available to us which have been created or recorded by us?
- Earned Data: which data do we receive from our customers and partners?
- Paid Data: which data can we buy from third parties (Third-Party-Data, Data Marketplaces) or trade in for our own data (Data Exchange)?
- Public Data: which data is publicly available (Open Data)?
Furthermore the Data Landscape Canvas differentiates between different kinds of data:
- Raw Data is data in its original form (for example measurement data).
- Derived Data has already been refined to some extend for example by cleansing or anonymizing it.
- Link Data allows to bring data from different sources in relation to each other.
The Data Landscape Canvas is available for free under a Creative Commons license: you may use and modify the canvas as long as you cite Datentreiber in particular as the source.

We drive your business forward.

We drive your business forward.
We drive your business forward.
How Can I Start?
Seminars
Get to know our Data Strategy Design Method in our practical seminars:
- For beginners: Data Strategy & Culture
- For rising stars: Data Design Thinking
- For advanced designers: Data Business Consulting
Cross References

Here you can find further canvas and information concerning Data Strategy Design:
License Terms
You are free to:
Share — copy and redistribute the canvas in any medium or format
Adapt — remix, transform, and build upon the canvas
for any purpose, even commercially.
Under the following terms:
Attribution
ShareAlike
We drive your business forward.
Subscribe to our newsletter:
Receive all relevant blog articles, new seminar dates, special conference offers and much more conveniently by email. As a welcome gift, we will send you a link to download our Datentreiber design book (in German) and, for a short time, the article ” Data Thinking: mehr Wert aus Daten” in PDF form after your registration.
By clicking ‘Subscribe to our newsletter’ you agree that we process your information in accordance with our privacy policy.
