If you follow our series on data strategy design using the Datentreiber method from the beginning, you already know that this is the fifth article in our six-part series. If not, you can also start with the first article in the series and learn how smart goals and the right analytics can help you find your way to the data-driven enterprise.
It is recommended to read the fourth article in the series first. It introduces you to the Data Strategy Canvas which helps you think through a use case conceptually. The Data Landscape Canvas then supports you in detailing this use case with regard to the required data sources. More about this later.
On our website, the Data Landscape Canvas – like all canvas already presented in the article series – is also available as open source. In addition, it will be explained in the Data Design Thinking seminar in a practice-oriented way. This is part of the training on data strategy design which Martin Szugat offers with his strategy consulting Datentreiber. Based on an example chosen by the group, an entire use case from value proposition to data management is worked through together.
Which Data Sources Do You Need?
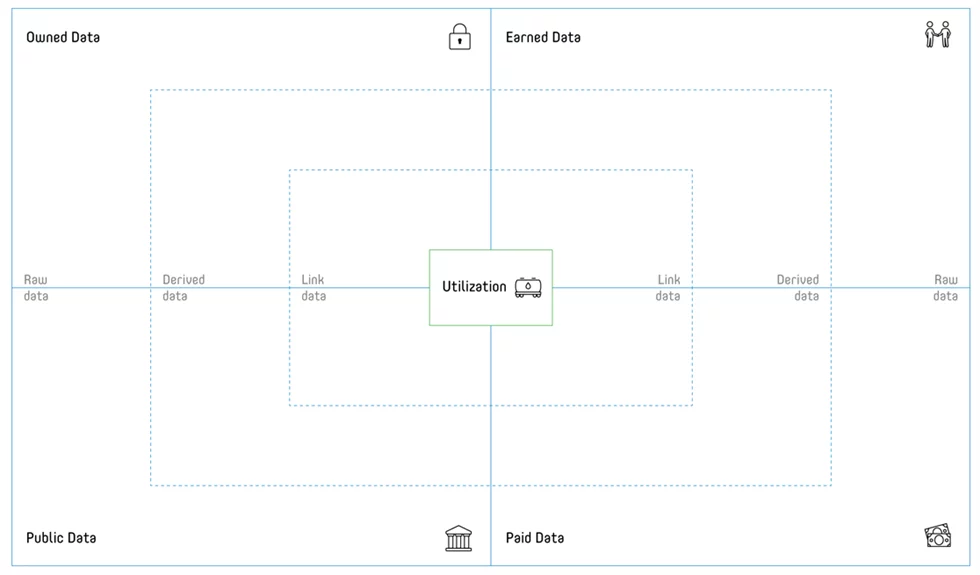
The Data Landscape Canvas consists of four quadrants. These subdivide the data in the data sources according to their origin:
• Owned data
• Earned data
• Paid data
• Public data
In the middle of the canvas is the field Utilization. This is also your starting point if you want to further refine a use case of the Data Strategy Canvas, as mentioned above. Another possibility is to take over the use case from the Analytics Maturity Canvas which we have also already presented here.
After you have placed a use case in the center of the canvas, work on the four quadrants clockwise. You should answer the following questions in each section:
- What data of the specific type helps you implement the use case?
- Which data sources are available and which of them have already been exploited?
- Which data sources are still needed?
You will inevitably encounter open questions and critical assumptions. You should note and evaluate these accordingly. On this basis you can then derive a prioritization for your next steps.
Does your use case depend on the completion of a data integration project that is still in the planning phase? Do you need to connect data from systems that have not yet been integrated (for example, data from your CRM system with your web analytics tool)?
The aim is to be clear on a conceptual level about which questions need to be answered first to ensure feasibility. This will reduce the risk of a (late) rude awakening. This can occur, for example, if you confront a blocker during implementation.
Of course, it is also possible that you identify an (initially) unsolvable problem. If this is the case, you should return to your use cases and re-prioritize. This should definitely not be seen as a failure. Instead, you have not wasted any resources, except paper and pencil, on a project that is (currently) not feasible.
In What Form Is Your Data Available?
In addition to the origin, the Data Landscape Canvas also allows a subdivision of data according to granularity. This is done from the outside to the inside in the following three areas:
- Raw data
- Derived data
- Link data
Depending on the application, it may be necessary to have the data available in different forms. If, for example, you purchase derived data (such as customer survey data aggregated to certain characteristics), but need raw data for your purposes, you should quickly answer the question at what price you can get this raw data or whether you can get it at all (anonymization of survey data).
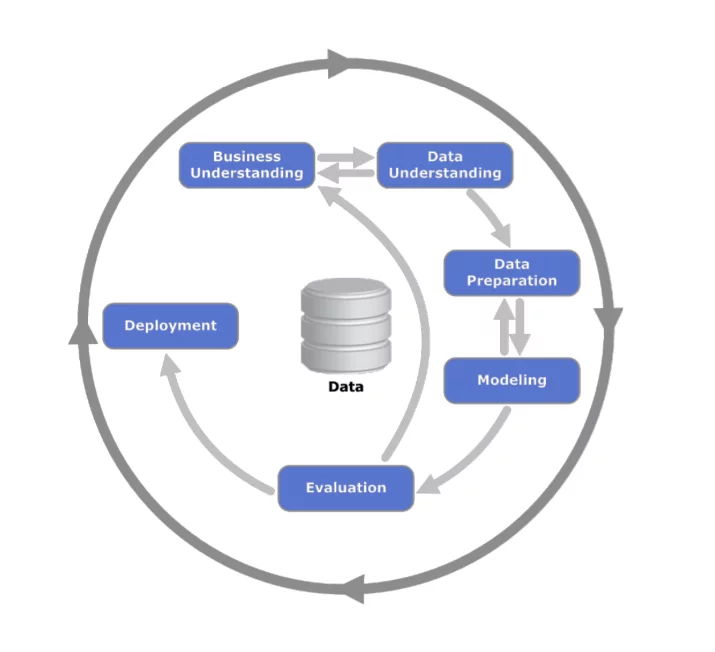
The understanding of business requirements (‘business understanding’) and the possibilities of the data (‘data understanding’) is a central step in creating a data-based solution – also according to the Cross-Industry Standard Process for Data Mining (see figure)
Another important role plays the link data. It enables you to merge data from different systems. A simple example is the connection of customer data from an ERP system with a CRM system using a unique customer identifier.
However, if both systems carry different IDs for the same customer and the data link is central to your use case, a critical question will be how to merge the data.
You Can Also Get an Overview First
In addition to the previously described process from the use case to the data sources, you can also use the Data Landscape canvas to explore the data landscape of your company in general. The starting point is thus the data or the data sources.
By categorizing the data according to origin and granularity, you ultimately have a good picture of what data you have, how it is distributed, and where there are gaps. Nevertheless, all of your considerations should at some point move towards use cases. Only in combination with these data can really deliver added value.
You don’t want to work on a specific use case but still want to limit the thematic field? Simply define a broader application area (e.g. digital marketing) centrally in the canvas. Doing so, you can ensure that the canvas is processed in a targeted manner.
Conclusion and Outlook
This fifth article in our series on data strategy design introduced you to the Data Landscape Canvas. It allows you to check the availability of the raw material of the use cases of your data strategy in advance of a possible implementation. This enables you to identify potential problems with your data at an early stage and react accordingly.
The sixth and final article: Hit the Sweet Spot With Your Data Strategy (6/6) in the series of articles deals with a complete overview of the Data Strategy Design.
The following other articles have been published in this series:
Note: Author of this article, which was originally published in German language and in full length on the Datentreiber blog, is Martin Raffeiner, Managing Director at datenbotschafter consulting.
Did we awake your interest in the development of data strategies? Then take a look at our Datengipfel Seminars Data Strategy & Culture for beginners and Data Design Thinking for advanced participants. Or contact us if you have any further questions.
